
this one’s about Levenshtein distance and how to find a needle in a haystack. again nothing revolutionary but might be of some use.
for my latest project I had to create a name selector that would pick up a name amongst over 30.000 preselected names (31.506 to be precise).
Q: how to instantiate a 30.000+ items long array?
A: you can’t. it will (surely) cause a stack overflow.
this instructive lesson was worth the subsequent reboot.
so I split my list into smaller pieces that I cleverly organized by first letter:
names beginning with an A, names beginning with a B, [...sparing your nerves...] and names beginning with a Z.
Q: so can I instantiate each array now?
A: you can’t. it will (most likely) cause a stack overflow.
Q: then what ?
A: then you can take a CSV string and use the split( ‘,’ ); method to turn it into an Array or feed a Vector.< String > as follow:
//
var a:Array = String( "the,hell,of,a,long,string" ).split(',');
//
//or if you want to feed a Vector.< String >:
var a:Vector.< String > = Vector.< String >( String( "the,hell,of,a,long,string" ).split(',') );
//
or at least this is what I came up with after a pretty nasty struggle.
you don’t believe me, do you ?
- crash my computer down with a direct instantiation of those 3829 names. (file is 42Ko)
- take your time to gently split those 3829 names. (file is 30Ko)
I guess the nested memory allocation of 4000 Strings in an Array object is a bit brutal and that performing a splitting operation is far less painful (even though it IS painful).
an elegant solution would be to perform requests on a DB, in my case I had to embed all the names within the app.
if the first test works for you, please write a comment and describe your hardware / software config. I am curious.
so this being done, I’ve implemented a Levenshtein distance to select the X best candidates after a given stem.
I took this script: LEVENSHTEIN DISTANCE BETWEEN WORDS and ‘optimized’ it a bit mostly using a linear Vector.< int > instead of a 2D Array & not using Math.min but a tertiary operator instead.
strangely enough, the array version perfomrs better on small strings.
that was nice yet not enough ; the search would bubble up some unexpected results while ignoring the best candidates (stupid machine). so I’ve added a couple of tricks:
- splitting the big array into smaller ones was a relevant idea: first thing I do is to switch on the first letters and get the correspondng array. it prevents us of scanning 30.000 items each time and cuts it down to (at worse) a tenth of this amount (“A”=3829 items in this case)
- if the stem is made of one letter only, a slice of the X first entries of the array is returned. too many candidates would match ; no use to return the list of the shortests words.
- then we compare the stem to each entry of the list, if we have a perfect match, a one item array is returned.
- we don’t need to take into account the words which length is shorter than the stem.
- next condition specifies that the candidate should begin with the stem (str.substr(0, stem.length)==stem): as the name is built up “chronologically” if the candidate doesn’t contain the stem, it is discarded.
- finally, the levenshtein distance is performed on each valid candidate, the X candidates that get the smaller cost are returned.
here’s a demo:
- so here’s the NameSelector class containing 30000+ names and that performs the steps descirbed above (130Ko \o/)
- and the code for the example above
the first time you call it might take a fair amount of ms (+/- 50 for me) ; it initializes the arrays, after which the requests take at worse 25ms on the (my) debug player.
a good thing is that the longer the stem, the faster the search. a stem made of 2 letters is the worst case to compute for there might be very many candidates matching all conditions above. on the contrary, a 5 letters’ stem will take almost not time.
Also notice that it doesn’t alphabetically sort the results i.e. the stem ‘no‘ returns :nox, noä, noy, noa, noe, nor, noah… when obviously noa should be first, then noä, noe, nor, nox & noy. this would involve an extra pass of sorting.
this was convenient enough so I used it as such.
( in a twit, jeff winder was noticing that french people always put a ‘but’ somewhere in their sentences, even when they agree with something, so ) BUT
I felt something could be done to improve the thing a bit so I started looking further.
as the levenshtein distance is not taking into account the letters themselves, my first idea was to check the distance between the letters of the strings to compare.
so I gave the alphabet’s letters an index (well done einstein!) and did something like this:
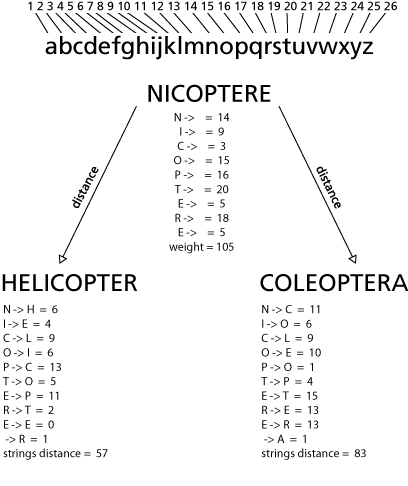
this little trick shows I am closer to an helicopter than a coleoptera which is somewhat reassuring.
BUT mostly it is rather cheap in terms of computation as the code for the stringDistance method goes like:
private var alphabet:String = 'abcdefghijklmnopqrstuvwxyz';
private var specialChars:String = 'áÁâÂàÀåÅãÃäÄçÇéÉêÊèÈëËíÍîÎìÌïÏñÑóÓôÔòÒØõÕöÖšŠÐþúÚûÛùÙüÜýÝÿŸ';
private var replaceChars:String = 'aaaaaaaaaaaacceeeeeeeeiiiiiiiinnooooooooooossdpuuuuuuuuyyyy';
private var i:int, count:int, total:int, value:int, id0:int, id1:int;
private var char0:String, char1:String;
public function stringDistance( string0:String = '', string1:String = '' ):int
{
total = 0;
count = ( string0.length > string1.length ) ? string0.length : string1.length;
for ( i = 0; i < count; i++ )
{
char0 = string0.charAt( i );
char1 = string1.charAt( i );
//both char0 & char1 are set : calculates the distance
if ( char0 != '' || char1 != '' )
{
id0 = specialChars.lastIndexOf( char0 );
if ( id0 != -1 ) char0 = replaceChars.charAt( id0 );
id1 = specialChars.lastIndexOf( char1 );
if ( id1 != -1 ) char1 = replaceChars.charAt( id1 );
value = ( alphabet.lastIndexOf( char1 ) - alphabet.lastIndexOf( char0 ) );
total += ( ( value < 0 ) ? -value : value ) + 1;//+ 1 otherwise the distance to A would be 0
}
//one of the values is not set, adds 1 as it'll take one char to fill the blank space
else
{
total++;
}
}
return total;
}
replacing the special chars, and computing the distance. unfortunately, using this method alone is not enough, BUT if you perform it right after the Levenshtein distance and add a blank space at the end of the stem, this little fella will help nicely.
here’s a test where you can enable/disable the distance check:
not only are the items sorted alphabetically but you’ll get relevant results first: a relevant word is not necessarily the closest Levenshtein neighbour of the stem.
for instance: the stem ‘kor‘ will return:
kora, kore, kori : ok, obviously 4 letters are close to 3 then koren a 5 letters word which is ‘closer’ to the stem than kory, koraly, korene, korien, korine, korzun…
then I had another idea, checking the similarity of the words.
I wanted to code something that would recognize the tokens like:
- nicoptere and helicopter
- nicoptere and coleoptera
and give this type of candidates a consequent advantage.
that’s when I found out that this was almost like an olympic sport: string metrics
by the way the article specifies that :
The most widely known (although rudimentary) string metric is Levenshtein Distance
there you’ll find an excellent resource about all the algorithms stringmetrics
in some way it relates to DNA sequence analysis…
I also learnt about the soundex, metaphones & double metaphones techniques and found it really interesting BUT too hard to port as compared to what I intended to do.
+ both algos are language specific : what works for english won’t work for german or italian or swedish.
not talking about french where we have a shitload of digraphs (‘gn’, ‘ei’, ‘oy’, … ), trigraphs( ‘amp’, ‘oin’…), quadrigraphs ( “oing”… ) which makes the switch lists very long to parse.
some clever people have already ported both algos to actionscript though:
so that’s where my researches ended up. I’ve had a couple of stupid ideas on the way, I’m eagerly waiting for monday to put them into practice.
thanks for reading this long… string :)
my beloved readers wrote…